Crash protection¶
Crash protection gives you the ability to alert when the application server is experiencing issues and prevent application servers from crashing.
Crash protection attempts to keep your server alive by watching for and preventing (or minimizing) the effects of the following scenarios, which have been identified as common causes for outages:
-
Requests taking too long are often an indicator of poor code design. In interactive systems like the web, requests must run in as short a time as possible. It's often preferable to receive an error message rather than continue waiting for a request which may never complete.
-
Too many requests running simultaneously often leads to resource starvation, and although it's usually possible to tune this using the J2EE engine itself, the system must usually be restarted for it to take effect – and the option is usually well hidden. The majority of J2EE engines – including Adobe's JRun – control resource access using thread pools, and having too many requests running at once can reduce or exhaust these pools to the state where it's no longer possible to recover the system, leading to a costly restart.
-
Exhausted memory occurs very frequently in production environments. On shared installations as well as dedicated servers there never seems to be enough memory. Approaching memory margins is a sign that the server is overloaded, or one or more requests are creating a lot of objects and using more than their fair share of storage.
-
Exhausted CPU due to an expensive request, frequent Garbage Collection and CPU intensive background tasks has the potential to cause degraded performance for all applications running on both the application server and the server itself.
Protection types¶
We designed three protection rules to counter these common situations. There's no need to alter any J2EE engine settings to take advantage of these rules, and no container restart is required for them to take effect.
Using these rules, either individually or in combination, FusionReactor can keep a server alive in a marginal situation for much longer than it would otherwise be available. In the vast majority of cases, Protection rules can keep a server up and responding long enough for the marginal situation to clear, allowing processing to continue normally.
WebRequest Quantity Protection¶
Any request which runs longer than a given threshold causes this rule to fire.
WebRequest Timeout Protection¶
Once the number of simultaneous requests reaches this threshold, further incoming requests cause this rule to fire.
WebRequest Memory Protection¶
Once memory has breached this threshold (specified as a percentage of total), further requests cause this rule to fire.
WebRequest CPU Protection¶
Once the instance CPU has breached this threshold (specified as a percentage of total), further requests cause this rule to fire.
Email alert¶
Configure your FusionReactor instance to send an email when Crash Protection is fired. To do this you need to setup the email configuration and enable notification emails in the Crash Protection Settings.
To avoid a flood of email in marginal situations, notification can be turned off completely, or can be set to only send email once in a given period – by default one minute. All three survival strategies are available for each of the three rules, except Timeout Protection, which can't use the Queue rule, since the requests it monitors can't be queued once they've started.
Email content¶
Email title¶
The email title contains the nature of the Crash Protection, followed by a title to indicate that the email was sent from Crash Protection and finally the FusionReactor instance in which Crash Protection was fired in. Below is a list of all the types of Crash Protection emails that you will ever see.
- [Timeout Protection] FusionReactor Protection Alert [FusionReactor URL]
- [Memory Protection] FusionReactor Protection Alert [FusionReactor URL]
- [Request Quantity Protection] FusionReactor Protection Alert [FusionReactor URL]
This is followed by a title in the email body as well.
Crash protection (EnGuard) information¶

The Crash Protection section shows the information of the actual trigger. This includes the following information:
| Field | Description |
|---|---|
| Protection Type | The Protection type that was triggered (e.g. Timeout) |
| Triggered At | The time the request was triggered. |
| Next At | The time at when an email event can be triggered again. This corresponds to the Protection Email Interval value in Email Settings. |
| Actual Value | The value of the type of Protection that was triggered (e.g. 10 requests were concurrently trying to run which caused the email to be sent). |
| Threshold | The threshold of the Protection that was triggered (e.g. A quantity threshold of 1 request was set which was surpassed). |
Server load¶

The Server Load section gives a brief overview of the state of the server at the time of the Protection trigger. The includes the following information:
| Field | Description | Format |
|---|---|---|
| Requests | Information regarding the start of all Requests at this instance in time. | Active Requests / Average Execution Time (ms) |
| JDBC | Information regarding the state of JDBC Requests at this instance in time. | Active JDBC Requests / Average Execution Time (ms) |
| Heap Memory Usage | The state of memory usage. | Used Memory / Max Memory (Percentage) |
| CPU | The state of CPU usage. | Instance CPU (%) / System CPU (%) |
Request information¶
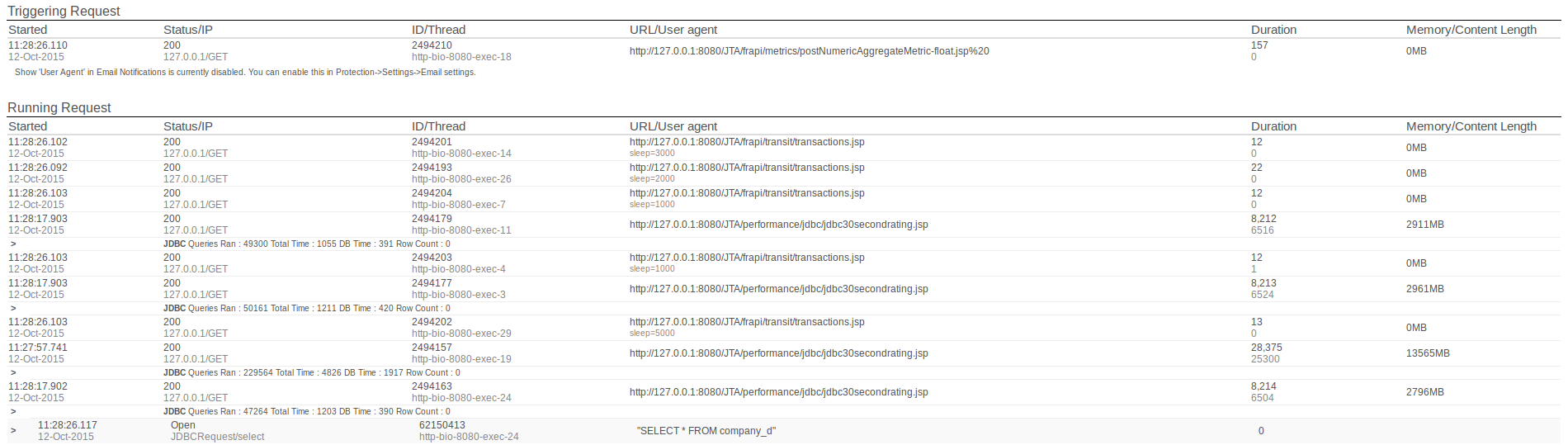
The Request Information section tells the user what request caused the Crash Protection trigger, and what other requests were being processed during the time this event occurred.
These tables show the following information:
| Field | Description |
|---|---|
| Started | The time that processing of this request begun. |
| Status/IP | The status code of the request and the IP of the request sender. |
| ID/Thread | The Global Request ID of the request and the Thread this request was processed on. |
| URL/User Agent | The request address with the user agent. |
| Duration | The time the request was being processed for and the time CPU was used for underneath. |
| Memory/Content Length | The amount of memory allocated to the transaction in MB. |
Stack traces¶
In the Crash Protection Email, stack traces of all threads running are dumped in order to help with pinpointing any issues. For information on how to use these stack traces effectively, it is advised to read the Stack traces section.
Survival strategies¶
Queue¶
This strategy attempts to alleviate the marginal situation by temporarily pausing incoming requests until the condition which caused the rule to fire no longer exists.
The length of the queue can be specified, after which requests will be terminated regardless of the survival strategy (queue expiry).
There is no limit on the size of the queue, so if a large quantity of requests are present they will consume tracking resources inside FusionReactor (albeit temporarily). This strategy is therefore best used on systems with sufficient memory, or on systems where the volume of requests is known and not expected to become prohibitive.
Reject¶
This strategy rejects requests. The request is summarily rejected and not allowed to proceed inside the J2EE engine. The abort strategy – redirect to URL or display of fixed message – is applied prior to the abort action.
Abort¶
When used with the Timeout Protection, FusionReactor uses strong thread manipulation techniques to make sure requests are stopped. If a request holds ownable synchronizers, FusionReactor will not use a thread abort since this could leave the system in a hung state. Instead, it will write a "Transit - Locks" context onto the request (which you can see as a tab in Request Details), detailing all the locks it found.
In all abort actions, FusionReactor will process the terminating requests for statistical and tracking purposes, unless Stop Tracking is set.
Risks & restrictions of request abort¶
JVM thread aborts¶
Java provides two types of locks to software running in the JVM: VM Monitors and Ownable Synchronizers.
When FusionReactor tries to stop a request, it first does this by flagging the request for halt, which it then performs when the request next outputs something to the browser. This is soft kill.
If the thread is not outputting, it proceeds to hard kill.
What happens next depends on which type of lock is in use by your J2EE software.
When a hard kill is performed, any VM Monitors are automatically freed by Java, with (almost) no side effects – the system continues normally.
Any Ownable Synchronizers are not freed - they remain in the same state prior to the kill. If the request owned such a synchronizer, it will now never be freed, since its owner has been killed. This usually leads to a system locking up and not processing web requests within a very short time.
FusionReactor will not proceed to hard kill if it detects ownable synchronizers are in use by a request. If this is the case, FusionReactor writes a transaction context onto the request containing a list of locks it found (this can be seen in Request Details under the Transit - Locks tab) and the request is allowed to continue.
Native-bound threads¶
Due to restrictions in the JVM, it is not always possible to immediately stop a thread. If a thread is currently engaged in a blocking native operation, i.e. performing I/O in a JNI method (sockets are a good example of this) then the JVM will not be able to abort the thread until it completes.
For this reason, you may not see requests disappear immediately when aborted with Protection or killed manually from the FusionReactor Administrator.
We're continuing to investigate this problem – which is a restriction of the Java virtual machine – and will release an updated version of FusionReactor when we have a solution.
J2EE containers & dead threads¶
After aborting a thread, FusionReactor processes the requests for statistical and display purposes inside the FusionReactor Administrator, then disposes of the original thread object by returning it to the J2EE engine.
Although the object no longer represents a valid thread, some engines do not check this, assuming the thread to still be runnable, and return the object back to their internal thread pool.
In some cases, this object can then be picked by the pool to run a new incoming request. This will then fail immediately, at which point the engine will remove the thread from the pool. The client then sees an error message, usually accompanied by a HTTP status 500 – Internal Server Error.
Again, this happens infrequently and is preferable to a total outage. As the sophistication of J2EE servers grows, this problem is diminishing.
Restrictions¶
Protection restrictions are designed to let you specify which pages you want to be monitored by the Protection system, or alternatively, which pages you do not wish to be monitored. To select which mode the Restrictions page works in, change the Restrictions option on the Protection Settings page. The Protection Restrictions page has two main areas. At the top of the page there is a form for you to enter new restrictions and below this is a list of all existing restrictions for this feature.
Creating restrictions¶
Rules are evaluated from top to bottom, and the first one which fires causes the engine to stop evaluating any further rules.
The Restrictions Engine matches each rule against components of the request URI. The exact components used during the match are selectable using the fields on the rules form.
The exact options available depend on the current mode of the engine: in Protect mode, the Statistics option is not available – all requests which match a rule are tracked for timing statistics. The labels used also change to reflect the mode of the system, and the make the meaning of the rule easier to understand.
Request¶
These two fields define the match mode of the rule, and the actual match string. The drop-down box specifies whether the text field is an exact string match, or whether the field contains a Java Regular Expression.
The remaining options tell the engine exactly which request fields to match against the entered string.
Hostname¶
If enabled, this field specifies that the string begins with a
hostname. This allows rules to target specific pages when addressed
by multiple sites. The value of this field should match the HTTP 1.1
'Host' header. No scheme (http:// or https://) should be applied.
This header is used by web servers, browsers and J2EE containers to
differentiate requests for multiple websites which may reside on the
same physical system.
A later section will illustrate how to use this feature to protect only certain page requests.
Parameters¶
This setting specifies whether FusionReactor will differentiate pages based on their URL (GET) parameters. A common design pattern is to change the behavior of a request based on the information provided as URL variables.
An example of this might be a doAction.jsp page, whose action is specified as a parameter. Some behaviors of this page should be exempt from protection (doAction.jsp?action=PopulateDataWarehouse, for example), while some should be observed and tracked (doAction.jsp?action=ServeFile).
This setting allows FusionReactor to treat the two requests separately, and decide whether to protect them based on the URL parameters.
Exclude from¶
(in Protect mode, this field is called Protection Type).
Specifies which specific protection is affected by this rule.
-
If the engine is in Exclude mode, this field specifies which protections any matching requests will be exempt from – either Timeout Protection or All Protection. If exempt from only Timeout Protection, a matching requests will still be protected by Request Quantity Protection (i.e. will be rejected if the request load is too high) and Memory Protection (i.e. will be rejected if the memory demand is too high). If exempt from Timeout Protection, requests will be allowed to run to completion, provided neither the Memory nor Request Quantity protections are activate.
-
If the engine is in Protect mode, this field specifies which protections will apply to any matching requests – either Timeout Protection or All Protection. Any requests which don't match will proceed into the J2EE container unprotected.
Statistics¶
(only available in Exclude mode)
If a request matches a rule and is therefore excluded from protection, this setting specifies whether its timing values will still contribute to FusionReactor metrics.
Examples¶
Excluding named batch jobs from timeout protection.¶
| Configuration | Value | |
|---|---|---|
| Active Protections | Timeout Protection @ 8 seconds | |
| Engine Mode | Exclude | |
| Rule | Exact match | /scripts/CleanUpDatabase.jsp |
| Exclude from | Timeout Protection | |
| Page Decisions | /scripts/CleanUpDatabase.jsp?db=MyDatabase | Ignored |
Exclude a page anywhere it occurs, we can use a regular expression.¶
| Configuration | Value | |
|---|---|---|
| Active Protections | Timeout Protection @ 8 seconds | |
| Engine Mode | Exclude | |
| Rule | Regular Expression | (.*)CleanUpDatabase.jsp |
| Exclude from | Timeout Protection | |
| Page Decisions | /scripts/CleanUpDatabase.jsp?db=MyDatabase | Ignored |
| /site/scripts/CleanUpDatabase.jsp | Ignored |
Similarly, if all our batch scripts were named batch?<job>.jsp*, we could also ignore them with an appropriate regular expression.
| Configuration | Value | |
|---|---|---|
| Active Protections | Timeout Protection @ 8 seconds | |
| Engine Mode | Exclude | |
| Rule | Regular Expression | (.)batch(.).jsp |
| Exclude from | Timeout Protection | |
| Page Decisions | /scripts/batchCleanUpDatabase.jsp?db=MyDatabase | Ignored |
Include specific hosts¶
If we wanted to include a specific host in Crash Protection only, the
following rule might suffice (NB the alias “testvm234” points to the
same machine as the first URL).
Active Protections
Timeout Protection @ 8 seconds
| Configuration | Value | |
|---|---|---|
| Engine Mode | Protect | |
| Rule | Regular Expression | int0234.intergral.com/(.*) |
| Protection Type | All Crash Protection | |
| Hostname | Check | |
| Page Decisions | http://int0234.intergral.com/testPage.jsp | Protected |
| http://testvm234.intergral.com/testPage.jsp | Ignored |
Include a specific action page¶
The following rule specifies an action page with many parameters which
normally takes a few minutes to complete when run in a certain mode. We
exclude it from Timeout Protection.
Active Protections
Timeout Protection @ 8 seconds
| Configuration | Value | |
|---|---|---|
| Engine Mode | Exclude | |
| Rule | Regular Expression | (.)mightyActionPage.jsp(.)action=backupDb(.*) |
| Protection Type | Timeout Protection | |
| Parameters | Check | |
| Page Decisions | Protected | |
| Ignored |
Modes¶
The Restrictions Engine decides which requests will be monitored by Protection, and which requests will be allowed to proceed unobserved. The engine is configured in FusionReactor Administrator in the Protection Restrictions section of the Protection > Settings page.
Any changes you make to these settings, as well as any changes you make to individual rules, become active immediately without necessitating any software restarts. This allows you to test and tune rules 'on the fly' - but remember that requests which are already running won't be affected.
The engine operates in one of three modes:
| Mode | Description |
|---|---|
| Disabled | in which the engine is completely bypassed. In this mode, all requests are monitored by Crash Protection if any protection is currently active. |
| Ignore matching requests | in which the engine will, by default, protect all requests. Any requests which match a rule are not monitored. |
| Protect matching requests | in which the engine will, by default, ignore all requests. Any requests which match a rule will be monitored. |
Engine Overhead
One of the chief design goals of the Restrictions Engine is that it demand very low overhead during the course of a request. The engine is optimized for very low CPU and memory demand and is almost undetectable when active. The Restrictions Engine can therefore be used even on very busy systems.
Engine rules¶
In order to decide whether a given request will (or will not) be protected, the Restrictions Engine evaluates a number of user-defined rules.
Each rule allows fine-grained specification of exactly which requests it matches.
A rule is specified as an exact match or a Regular Expression as defined by the relevant Java JRE specification. As well as the URL path, the following optional components can be used to define the rule:
-
The requested hostname – useful to differentiate requests on multi-homed systems
-
The URL parameters – useful for requests whose behavior changes according to their parameters
Additionally, each rule can specify whether pages matched by that rule will be protected by (or excluded from) all protections or just Timeout protection. If the list is running in exclude mode, in which all requests are protected by default, it's also possible to specify whether any excluded requests will still be tracked for statistical purposes (e.g. runtime tracking etc.).